
데이터 분석 또는 인공지능에 대해 처음 공부를 시작하면 대뜸 맨 앞에 등장하는 것 중 하나가 판다스Pandas이다.
몇 줄 설명을 읽어보긴 하지만, 그래서 뭐 어쨌다는 건지 도무지 와닿지 않는다. 그런 상태에서 무작정 코드를 따라 치기 시작하니 머리가 멍해질 수밖에 없다.
이번 글에서는 pandas란 무엇이고, 왜 필요한지, 어떻게 쓸 수 있는지 머릿속 의문점을 하나씩 풀어가며 이해해보자!

판다스Pandas 란 데이터를 분석하고 각종 처리를 할 때 이용하는 파이썬 언어 기반의 라이브러리이다.
pandas로 데이터를 표현하는 두 가지 핵심 방법(정확히 말하면 객체)이 있는데, 바로 데이터프레임DataFrame 과 시리즈Series 이다. 각각이 어떻게 생겼는지 예제 코드로 살펴보자.
데이터프레임 DataFrame
# 일단 pandas 라이브러리를 쓰려면 프로그램에 불러 와야 한다
# 관례적으로 pd라는 별칭을 이용한다
import pandas as pd
# dataframe을 만든다
pd.DataFrame({'Nanun': [0, 3], 'Zoey': [4, 2]}, index=['Apple', 'Banana'])실행 결과

위와 같은 표table 가 바로 데이터 프레임이다. 각 행row 과 열column 에 들어가는 값은 숫자는 물론, 문자나 불리언boolean 형태(True or False)도 가능하다.
시리즈 Series
데이터프레임이 표 형태인 것에 반해, 시리즈는 리스트 형태로 표현된다.
열column 이 하나인 데이터프레임이라고 생각하면 된다. 같은 맥락으로, 데이터프레임은 여러 column의 series를 딕셔너리 형태로 묶은 것이라고 볼 수 있다.
# series를 만든다
pd.Series([4, 5], index=['Apple', 'Banana'])실행 결과

그런데 우리가 분석이나 어떤 처리를 할 데이터는 위 예제보다는 훨씬 더 크고 많을 것이다.
한눈에 보기 어려운 많은 데이터가 어떤 개요와 경향을 가지고 있는지, 그 경향을 더 잘 해석하기 위해 다르게 표현할 수 있을지, 유독 튀는 이상한 값은 없는지 확인하고 조작하는 데 바로 pandas를 활용하는 것이다.
데이터 탐색 맛보기
곧바로 실전으로 넘어가서 데이터를 직접 조작해보자.
CSV 파일을 pandas를 이용하면 코드 단 한 줄로 데이터프레임 형태로 나타낼 수 있다.
*개인 취향을 적극 반영해 데이터셋dataset은 와인 리뷰로 정했다.
# 데이터를 불러 온다
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
# 불러 온 데이터가 어떻게 생겼는지 살펴보자
wine_reviews실행 결과

많아서 한 번에 다 확인할 수는 없지만, 일단 column을 보면 와인 산지와 와인의 이름, 포도 품종, 와이너리, 맛을 평가한 소믈리에의 이름과 평가 점수 등 다양한 정보가 있다. 보기만 해도 행복..❤
우선 데이터의 개요와 주요 값들을 살펴보며 이해도를 더 높여보자.
# 데이터의 총 개수 확인하기
wine_reviews.shape실행 결과

이 데이터셋은 총 14개의 column과 129,971개의 row 값을 가지고 있다.
# 첫 5개 row 살펴보기
wine_reviews.head()실행 결과

# 100점을 받은 와인의 산지와 품종, 와이너리 정보만 따로 보기
best_wines = wine_reviews.loc[wine_reviews.points == 100, ['country', 'province', 'variety', 'winery']]실행 결과
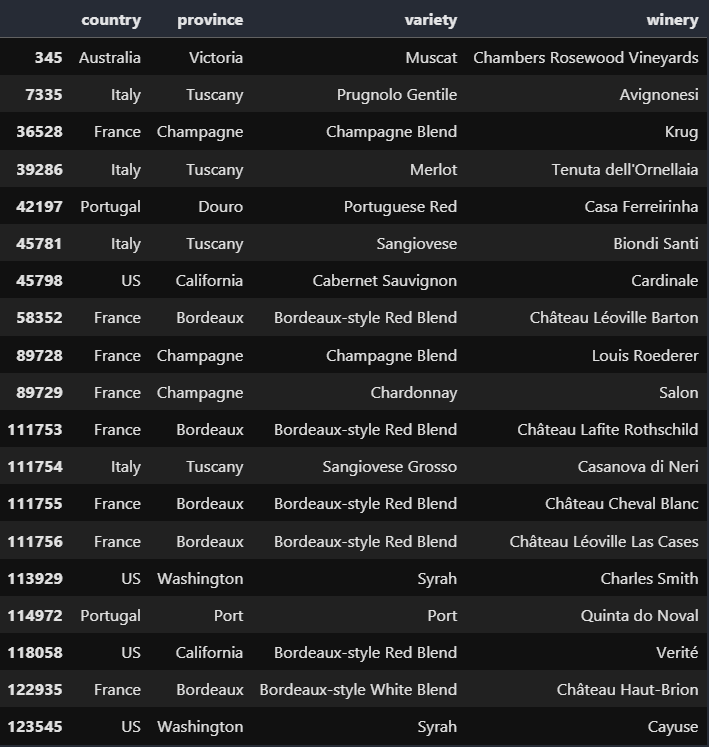
# 직접 세기 귀찮으니까 몇 개인지 물어보자
best_wines.count()실행 결과

만점을 받은 와인이 19개나 있다!
과연 어떤 나라가 최고의 와인을 가장 많이 배출하고 있을까?
# 만점을 받은 와인들을 국가별로 묶어 그 개수를 세어보자
best_wines.groupby(['country']).count()실행 결과

만점을 받은 19개 와인 중 무려 8개가 프랑스, 각 4개씩 이탈리아와 미국이 그다음으로 많은 것을 볼 수 있다.
크으으.. 역시! 와인은 프랑스지! 🍷
이제 순전히 사심을 따라 만점을 받은 프랑스 와인들만 골라서 자세히 살펴보자.
# 만점을 받은 프랑스 와인들의 산지, 포도 품종, 와이너리 이름을 살펴보자
best_wines.loc[best_wines.country == 'France']실행 결과

이를 통해, 비록 맛보기이지만 와인 입문자라면 알아둘 만한 몇 가지 진리와 같은 사실을 알 수 있다.
- 최고의 와인 산지는 역시 프랑스다.
- 그중에서도 레드 와인은 보르도, 화이트 와인은 상파뉴(영어 발음으로 샴페인) 지역이 최고다.
pandas로 데이터를 어떻게 요리조리 뜯어볼 수 있는지 아아아주 살짝 맛을 보았다.
이걸 시작으로 앞으로 할 수 있는 것들이 오조오억배는 더 많다! 그걸 나열해보면 대략 다음과 같다.
- 데이터프레임의 인덱싱 등을 활용한 데이터 조작
- 데이터셋 리팩터링 / 피보팅
- 데이터셋 병합 / 조인
- 데이터 결측치 처리
- 데이터의 각종 시계열 작업
- 다양한 파일 형식으로 데이터 읽거나 쓰기
- 고차원 데이터 처리
- ....
조금 느릴 수 있지만, 나름의 속도로, 즐겁게 알아가 보자! :)
번외) 판다스와 판다의 관계
결론부터 말하면, 전혀. 없어도 너무 없다. 😭
Pandas라는 이름은 계량 경제학에서 사용되는 용어인 'PANel DAta'의 앞 글자를 따서 지어졌다고 한다.
개인적으로 아쉬운(?) 점은 로고다. 사실 파이썬Python 도 비단뱀과는 직접적으로 아무런 관련이 없지만, 로고만은 비단뱀 두 마리가 서로 엉켜 있는 모습을 형상화한 것이다.
그러나 판다스의 공식 로고는 다음과 같다.

세로 네 줄은 가운데 들어간 색깔 덕분에 구분이 가능한데, 바로 pandas의 별칭 pd를 나타내고 있다.
약간 충격적인 사실은 그나마 이 로고가 꽤 준수한(?) 상태라는 것이다.
아래 이미지는 약 1년 전 리브랜딩 하기 이전의 판다스 로고라고 한다. ㅎㅎㅎ
이걸 보고 귀여운 판다 로고를 바라는 것은 무의미하다는 것을 깨달았다.
그냥 마음속에만 간직하는 것으로...🙃
'공부하며 성장하기 > 인공지능 AI' 카테고리의 다른 글
| 앙상블 학습(Ensemble Learning)이란? (2) | 2021.08.15 |
|---|---|
| 경사하강법(Gradient Descent)이란? (0) | 2021.07.27 |
| 수치 미분(Numerical differentiation)이란? (0) | 2021.07.27 |
| 퍼셉트론(perceptron)이란? (0) | 2021.07.21 |
| [단단한 머신러닝] 01/ 머신러닝은 뭘 하는 건가요? (0) | 2021.07.03 |