
최근 여러 YOLO 모델로 데이터를 학습시키는 과정에서 시간이 오래 걸려 고생했습니다.
데이터가 많아서라기 보다는 GPU 사용률(Utilization)이 평균 20%에도 미치지 못한 것이 가장 큰 원인이었어요.
하지만 여러 시도 끝에 결국은 사용률을 90% 이상으로 개선했고, 학습 시간을 3분의 1로 줄일 수 있었습니다.
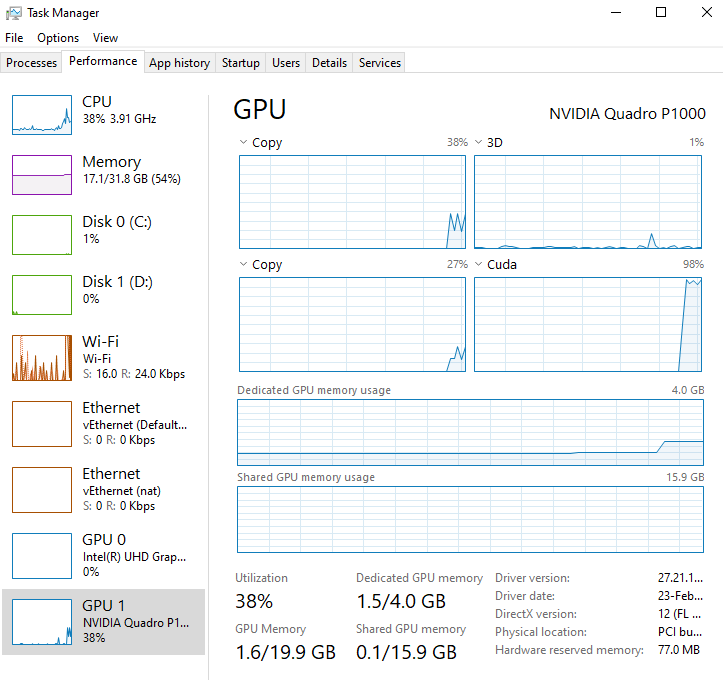
우선 제가 최종적으로 사용한 것은 아래 모델입니다.
YOLO 모델로는 Ultralytics에서 배포한 repository들을 많이 이용하실텐데, 제 경우에는 프로젝트에 맞게 수정하기가 까다로운 구조라고 판단해서 대신 아래 repository를 가져와서 사용했습니다.
GitHub - eriklindernoren/PyTorch-YOLOv3: Minimal PyTorch implementation of YOLOv3
Minimal PyTorch implementation of YOLOv3. Contribute to eriklindernoren/PyTorch-YOLOv3 development by creating an account on GitHub.
github.com
하지만 편리함 측면에서는 확실히 ultralytics의 모델을 이용하는 것이 좋기는 합니다.
즉 본인이 진행 중인 프로젝트에 맞게 특별히 수정이 필요한 경우가 아니라면 ultralytics의 모델 이용을 추천합니다.
더 추천하는이유들을 나열하면 다음과 같은 것들이 있으니 참고하시기 바랍니다.
- Wandb와 Tensorboard가 모두 구현되어 있어, 원하는 걸 골라 쓸 수 있다.
- 별도 코드 구현 없이 Detect 결과를 YOLO format의 txt 파일로 저장할 수 있다. 즉, 모델의 예측 결과를 새로운 학습 데이터로 사용함으로써 데이터 라벨링 수작업을 대폭 줄일 수 있다.
1. DataLoader의 pin_memory, persistent_workers=True로 설정
- pin_memory=True
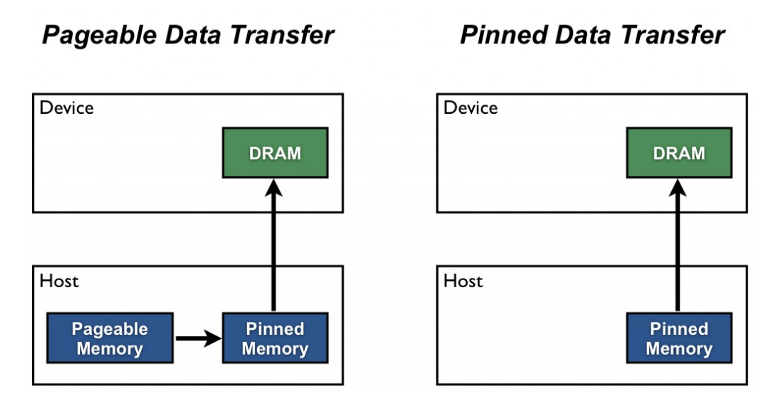
pinned memory는 아래 그림처럼 호스트(CPU)에서 디바이스(GPU)로 전송을 위한 staging area를 뜻합니다.
pin_memory를 True로 설정할 경우 입력 데이터를 pinned memory에 바로 로드하여 효율적으로 CUDA 연산이 가능하도록 합니다.
즉 CPU를 이용해 데이터를 가져와 메모리에 올리고, 이를 다시 GPU 메모리로 복사하는 과정에서 발생하는 병목 현상을 줄일 수 있습니다.
- 같은 이유로 pin_memory와 함께 num_workers도 조정하는 경우가 많은데, 제 경우에는 큰 차이가 없었습니다.
- persistent_workers=True
False일 경우 데이터셋을 로드할 때마다 workers를 새로 생성하는데, True로 설정하여 이를 계속 유지하도록 합니다.
# pytorchyolo/train.py
def _create_data_loader(img_path, batch_size, img_size, n_cpu, multiscale_training=False):
dataset = ListDataset(
img_path,
img_size=img_size,
multiscale=multiscale_training,
transform=AUGMENTATION_TRANSFORMS)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
num_workers=n_cpu,
pin_memory=True, # 여기 확인
persistent_workers=True, # 여기 추가
collate_fn=dataset.collate_fn,
worker_init_fn=worker_seed_set)
return dataloader
2. 학습 시 checkpoint_interval 조정
checkpoint_interval default 설정은 1로, 매 에폭(epoch)마다 checkpoint를 저장하게 됩니다.
제 경우 checkpoint를 저장하는 데만도 최소 30초 이상 소요됐기 때문에, 총 epoch에 따라 이를 5 또는 10 정도로 조정하였습니다.
# pytorchyolo/train.py
def run():
print_environment_info()
parser = argparse.ArgumentParser(description="Trains the YOLO model.")
parser.add_argument("-m", "--model", type=str, default="config/yolov3.cfg", help="Path to model definition file (.cfg)")
parser.add_argument("-d", "--data", type=str, default="config/coco.data", help="Path to data config file (.data)")
parser.add_argument("-e", "--epochs", type=int, default=300, help="Number of epochs")
parser.add_argument("-v", "--verbose", action='store_true', help="Makes the training more verbose")
parser.add_argument("--n_cpu", type=int, default=8, help="Number of cpu threads to use during batch generation")
parser.add_argument("--pretrained_weights", type=str, help="Path to checkpoint file (.weights or .pth). Starts training from checkpoint model")
# checkpoint_interval: 1 --> 10으로 조정
parser.add_argument("--checkpoint_interval", type=int, default=10, help="Interval of epochs between saving model weights")
parser.add_argument("--evaluation_interval", type=int, default=1, help="Interval of epochs between evaluations on validation set")
parser.add_argument("--multiscale_training", action="store_true", help="Allow multi-scale training")
parser.add_argument("--iou_thres", type=float, default=0.5, help="Evaluation: IOU threshold required to qualify as detected")
parser.add_argument("--conf_thres", type=float, default=0.1, help="Evaluation: Object confidence threshold")
parser.add_argument("--nms_thres", type=float, default=0.5, help="Evaluation: IOU threshold for non-maximum suppression")
parser.add_argument("--logdir", type=str, default="logs", help="Directory for training log files (e.g. for TensorBoard)")
parser.add_argument("--seed", type=int, default=-1, help="Makes results reproducable. Set -1 to disable.")
args = parser.parse_args()
print(f"Command line arguments: {args}")
3. batch size, subdivisions 조정
입력 이미지 사이즈를 고려해 batch size와 subdivisions(mini-batch size)를 조정하면 도움이 됩니다.
몇 가지 옵션을 직접 적용하면서 비교해보고 적절한 값으로 넣으시면 됩니다.
* 번외로 학습률(learning rate)을 0.0001처럼 너무 낮게 설정할 경우, epoch이 계속 진행돼도 mAP가 0.0000으로만 나타날 수 있습니다. 최소 0.001 이상으로 설정하는 것을 추천합니다.
# config/custom-yolov3.cfg
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64 # 해당 프로젝트/데이터 성격에 맞게 조정
subdivisions=16 # 해당 프로젝트/데이터 성격에 맞게 조정
width=416 # 해당 프로젝트/데이터 성격에 맞게 조정
height=416 # 해당 프로젝트/데이터 성격에 맞게 조정
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001 # 0.0001로 할 경우 gradient update가 너무 느릴 수도 있음
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
4. Image Resize 후 전처리 수행하도록 수정
마지막으로, 특히 제가 진행 중인 프로젝트에 가장 적합했던 방법입니다.
원래 코드는 데이터를 불러와서 전처리를 모두 수행한 이후에 resize하고, 이를 모델에 입력하는 순서입니다.
그런데 제가 가진 데이터셋은 이미지 크기가 비교적 커서, 큰 이미지를 그대로 전처리하는 과정에서 CPU 로드가 매우 크게 걸렸습니다.
때문에 아래처럼 중간에 이미지를 resize하는 코드 한 줄을 추가함으로써 훨씬 더 작은 이미지를 빠르게 전처리하도록 했습니다.
덕분에 CPU 사용률은 100%에서 50% 수준까지 줄어들었고, 반대로 GPU 사용률은 거의 100%까지 끌어올릴 수 있었습니다.
# pytorchyolo/utils/datasets.py
class ListDataset(Dataset):
'''중간 생략'''
def __getitem__(self, index):
# ---------
# Image
# ---------
try:
img_path = self.img_files[index % len(self.img_files)].rstrip()
img = np.array(Image.open(img_path).convert('RGB'), dtype=np.uint8)
# 여기서 중간에 이미지를 미리 resize해서 가져온 후 전처리하도록 수정
img = img.resize((1200, 900), Image.BICUBIC)
except Exception:
print(f"Could not read image '{img_path}'.")
return
# ---------
# Label
# ---------
try:
label_path = self.label_files[index % len(self.img_files)].rstrip()
# Ignore warning if file is empty
with warnings.catch_warnings():
warnings.simplefilter("ignore")
boxes = np.loadtxt(label_path).reshape(-1, 5)
except Exception:
print(f"Could not read label '{label_path}'.")
return
# -----------
# Transform
# -----------
if self.transform:
try:
img, bb_targets = self.transform((img, boxes))
except Exception:
print("Could not apply transform.")
return
return img_path, img, bb_targets
아래 자료를 참고했습니다.
'공부하며 성장하기 > 인공지능 AI' 카테고리의 다른 글
| 이미지 인코딩(Encoding)과 디코딩(Decoding) 과정 이해하기 (2) | 2022.10.18 |
|---|---|
| Yolov5에서 ModelEMA와 model fuse가 의미하는 것 (2) | 2022.09.24 |
| 서포트 벡터 머신(Support Vector Machine) (0) | 2022.02.21 |
| 딥러닝 오차 역전파(Back-propagation) 정확히 이해하기 (0) | 2022.02.15 |
| [한 줄 정리] 베이지안 최적화(Bayesian Optimization) (0) | 2022.02.14 |