
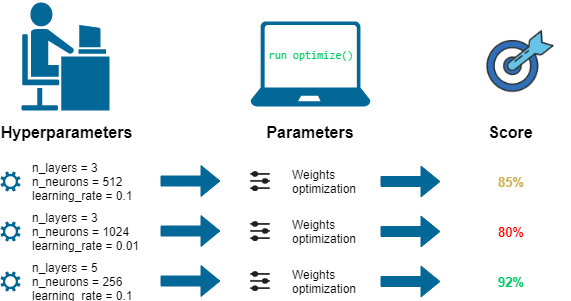
하이퍼파라미터(Hyperparameter)란, 모델이 학습하면서 최적의 값을 자동으로 찾는 것이 아니라
사람이 직접 지정해 주어야 하는 변수를 말한다.
반면 파라미터(Parameter)는 가중치나 편향처럼 모델이 학습을 통해 최적의 값을 찾는 변수이다.
아래 그림은 하이퍼파라미터와 파라미터를 직관적으로 이해할 수 있도록 도와준다.
대표적인 하이퍼파라미터의 종류에는 다음과 같은 것들이 있다.
- 학습률(Learning Rate)
- 비용 함수(Cost Function)
- 훈련 반복 횟수(Epochs)
- 은닉층의 뉴런 개수(Hidden Units)
- 규제 강도(Regularization Strength)
- 가중치 초기값(Weight Initialization)
- 미니 배치 크기(Mini-batch Size)
그렇다면 최적의 하이퍼파라미터 값은 어떻게 찾을 수 있을까?
그 네 가지 방법에 대해 살펴보자.
① 매뉴얼 서치 Manual Search
말 그대로 사람이 직관이나 경험에 기반해 직접 찾는 방법이다.
먼저 임의의 값을 대입해 결과를 살피고, 그 결과에 따라 값을 조정해가며 변화를 관찰하는 것이다.
값을 하나씩 대입해보고 조정하는 과정을 반복하면서 최적의 값을 찾는다.
② 그리드 서치 Grid Search
탐색할 하이퍼파라미터의 범위를 정해 두고 그 안에서 일정한 간격으로 값을 대입해보는 방식이다.
그러나 하이퍼파라미터의 개수에 따라 계산해야 할 차원이 기하급수적으로 늘어나기 때문에 탐색에 시간이 매우 오래 걸리고, 효율이 떨어진다. 더구나 grid 간격 이내에 최적 값이 있을 경우에는 찾을 수 없다는 단점도 있다.
③ 랜덤 서치 Random Search
그리드 서치와 마찬가지로 선험적인 지식을 이용해 하이퍼파라미터의 범위를 정하고, 무작위로 최적의 값을 탐색한다.
그리드 서치에 비해 더 효율적인 것은 물론이고 결과도 더 우수한데, 그 이유는 모든 하이퍼파라미터의 중요도, 즉 최종 정확도에 미치는 영향력이 각각 다르기 때문이다.

④ 베이지안 최적화 Bayesian Optimization
베이즈 정리(Bayes' theorem)를 기반으로 미지의 목적함수(Objective Function)를 최대화(혹은 최소화)하는 최적해를 찾는 기법이다.
매뉴얼 서치나 그리드 서치보다는 더 효율적이지만, 모든 문제에 대해 적합해서 일반적으로 적용할 수 있는 알고리즘은 아니다.
이론은 알겠는데, 실제로는 어떻게 구현되는 걸까?
예시 코드를 살펴보자.
# Grid Search
from sklearn.model_selection import GridSearchCV
grid_search = {
'criterion': [model.best_params_['criterion']],
'max_depth': [model.best_params_['max_depth']],
'max_features': [model.best_params_['max_features']],
'min_samples_leaf': [model.best_params_['min_samples_leaf'] - 2,
model.best_params_['min_samples_leaf'],
model.best_params_['min_samples_leaf'] + 2],
'min_samples_split': [model.best_params_['min_samples_split'] - 3,
model.best_params_['min_samples_split'],
model.best_params_['min_samples_split'] + 3],
'n_estimators': [model.best_params_['n_estimators'] - 150,
model.best_params_['n_estimators'] - 100,
model.best_params_['n_estimators'],
model.best_params_['n_estimators'] + 100,
model.best_params_['n_estimators'] + 150]
}
clf = RandomForestClassifier()
model = GridSearchCV(estimator = clf, param_grid = grid_search,
cv = 4, verbose= 5, n_jobs = -1)
model.fit(X_Train,Y_Train)
predictionforest = model.best_estimator_.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc4 = accuracy_score(Y_Test,predictionforest)# Random Search
import numpy as np
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import cross_val_score
random_search = {'criterion': ['entropy', 'gini'],
'max_depth': list(np.linspace(10, 1200, 10, dtype = int)) + [None],
'max_features': ['auto', 'sqrt','log2', None],
'min_samples_leaf': [4, 6, 8, 12],
'min_samples_split': [5, 7, 10, 14],
'n_estimators': list(np.linspace(151, 1200, 10, dtype = int))}
clf = RandomForestClassifier()
model = RandomizedSearchCV(estimator = clf, param_distributions = random_search, n_iter = 80,
cv = 4, verbose= 5, random_state= 101, n_jobs = -1)
model.fit(X_Train,Y_Train)
predictionforest = model.best_estimator_.predict(X_Test)
print(confusion_matrix(Y_Test,predictionforest))
print(classification_report(Y_Test,predictionforest))
acc3 = accuracy_score(Y_Test,predictionforest)전체 코드와 베이지안 최적화를 적용한 코드는 아래 링크들에서 찾을 수 있다.
아래 내용을 참고했습니다.
- 책 『밑바닥부터 시작하는 딥러닝』
- KDnuggets
- 블로그 - Data Analysis & Study
- 블로그 - 라온피플(주)
'공부하며 성장하기 > 인공지능 AI' 카테고리의 다른 글
| 선형 회귀(Linear Regression)와 경사하강법(Gradient Descent) (0) | 2021.08.23 |
|---|---|
| [Kaggle] Recruit Restaurant Visitor Forecasting Competition (0) | 2021.08.21 |
| 과적합(Overfitting)과 규제(Regularization) (2) | 2021.08.17 |
| 앙상블 학습(Ensemble Learning)이란? (2) | 2021.08.15 |
| 경사하강법(Gradient Descent)이란? (0) | 2021.07.27 |