![[Kaggle] Recruit Restaurant Visitor Forecasting Competition](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FlKcgC%2FbtrcLAi1ko5%2Fnl7RXO9ectYYvrKqkBIRh0%2Fimg.png)
Competition Overview 개요
- Kaggle Recruit Restaurant Visitor Forecasting Competition
- Sponsored by Recruit Holings.
- Held in Jan. 2018.
- Challenged to use reservation and visitation data to predict the total number of visiotrs to a restaurant for future dates.
- Will help restaurants be much more efficient and allow them to focus on creating an enjoyable dining experience for their customers.
- Submission & Evaluation
- Submissions are evaluated on the root mean squared logarithmic error(RMSLE).
- Submission file should contain two columns: id and visiotrs.
- id: Formed by concatenating the air_store_id and visit_date with an underscore.
- Should contain a header.
- Baseline Kernal
Data Integration & Exploration 데이터 통합 및 탐색
구글 코랩(Colab)을 이용했기 때문에 drive를 mount해야 데이터를 로드할 수 있다.
# Google Drive Mount
from google.colab import drive
drive.mount('/content/drive')
# Load dataset
dir_path = 'drive/My Drive/Colab Notebooks/Hackerthon1_210804/input'
data = {
'tra': pd.read_csv(dir_path + '/air_visit_data.csv'),
'as': pd.read_csv(dir_path + '/air_store_info.csv'),
'hs': pd.read_csv(dir_path + '/hpg_store_info.csv'),
'ar': pd.read_csv(dir_path + '/air_reserve.csv'),
'hr': pd.read_csv(dir_path + '/hpg_reserve.csv'),
'id': pd.read_csv(dir_path + '/store_id_relation.csv'),
'tes': pd.read_csv(dir_path + '/sample_submission.csv'),
'hol': pd.read_csv(dir_path + '/date_info.csv').rename(columns={'calendar_date':'visit_date'})
}
for d in data:
print(f"shape of {d}: {data[d].shape}")
우선 store_id를 store_id_relation.csv를 기준으로 air_store_id로 통일한다.
최종 output은 aire_store_id를 기준으로 하므로 hpg_store_id에만 있는 merge 방법은 'inner'로 하여 데이터는 drop한다.
# hpg_store_id를 기준으로 air_store 데이터와 통합
data['hr'] = pd.merge(data['hr'], data['id'], how='inner', on=['hpg_store_id'])
# 최종 output은 air_store_id가 기준이 되므로 hpg_store_id는 drop해서 id를 통일
data['hr'].drop('hpg_store_id', axis=1, inplace=True)
# air_reserve에 hpg_reserve 데이터를 추가
data['ar'] = data['ar'].append(data['hr'])
다음으로 date & datetime을 통일한다.
나중에 date 또는 datetime을 연산에 사용해야 하므로 모든 column의 값이 str 타입이거나 pandas datetime 타입, 둘 중 하나로 통일되어야 한다.
# 기존 visitor 데이터에 datetime column을 추가
data['tra']['visit_datetime'] = pd.to_datetime(data['tra']['visit_date'])
data['tra']['visit_date'] = data['tra']['visit_datetime'].dt.date
# 방문 요일을 column으로 추가
data['tra']['dow'] = data['tra']['visit_datetime'].dt.dayofweek
# datetime 타입으로 변환
data['ar']['visit_datetime'] = pd.to_datetime(data['ar']['visit_datetime'])
# visite_date column 추가 및 타입 변환
data['ar']['visit_date'] = data['ar']['visit_datetime'].dt.date
# 불필요한 column 삭제
data['ar'].drop('visit_datetime', axis=1, inplace=True)
data['ar'].drop('reserve_datetime', axis=1, inplace=True)# store_id와 date를 기준으로 방문 예정 인원 합치기
data['ar'] = data['ar'].groupby(['air_store_id','visit_date'], as_index=False).sum().reset_index()
# index 열은 중복되므로 삭제
data['ar'] = data['ar'].drop(['index'], axis=1)
# datetime 타입으로 변환
data['hol']['visit_date'] = pd.to_datetime(data['hol']['visit_date'])
# str 타입으로 다시 변환
data['hol']['visit_date'] = data['hol']['visit_date'].astype(str)
test 데이터셋도 위와 마찬가지로 column을 똑같이 만들어준다.
# id를 store_id와 date로 분리
data['tes']['air_store_id'] = data['tes']['id'].map(lambda x: '_'.join(x.split('_')[:2]))
data['tes']['visit_date'] = data['tes']['id'].map(lambda x: str(x).split('_')[2])
# 최종 output은 기존 id column 형태가 필요하므로 변수에 따로 저장
test_id = data['tes']['id']
# 기존 id column을 drop
data['tes'].drop('id', axis=1, inplace=True)
# datetime과 dow column 생성
data['tes']['visit_datetime'] = pd.to_datetime(data['tes']['visit_date'])
data['tes']['dow'] = data['tes']['visit_datetime'].dt.dayofweekdate와 day_of_week에 따른 visitor를 시각화해서 살펴 본다.
- 날짜에 따른 visitor의 경우, 2016년 7월부터 전체 visitor 수가 크게 증가한 것으로 보아, 데이터 수집 방식이나 환경에 변화가 있었던 것으로 보인다.
- 추후 데이터 전처리 과정에서 before 2016년 7월인 데이터는 exclude하기로 한다.
또 2017년 1월쯤 유독 visitor 수가 적다.
- 해당 기간의 데이터를 이상치로 판단할 수도 있지만, 그에 상응하는 2016년 1월 데이터를 사실상 알 수 없기 때문에 이상치라고 판단할 근거가 부족하다. 따라서 그냥 포함시킨다.
요일에 따른 visitor의 경우, 역시 금요일과 토요일에 가장 visitor가 많은 것으로 나타났다.
- 0~6은 순서대로 월요일부터 일요일까지를 의미한다.
# 날짜에 따른 전체 visitor 시각화해서 살펴보기
_tmp1 = data['tra'].copy()
# 요일별 visitor 시각화를 위해 데이터 저장해두기
_tmp_dow = data['tra'].copy()
# 불필요한 column drop
_tmp1.drop('dow',axis=1, inplace=True)
# visit_date을 기준으로 visitor 합계 계산
visitors_by_date = _tmp1.groupby('visit_date').sum()
ax = visitors_by_date.plot(figsize=[18,5], title='Visitors by Date')
# 요일별 visitor 시각화해서 살펴보기
# 불필요한 columns drop
_tmp_dow.drop(['air_store_id', 'visit_date', 'visit_datetime'], axis=1, inplace=True)
visitors_by_day = _tmp_dow.groupby('dow').sum()
ax = visitors_by_day.plot.bar(xlabel='Day(0: Mon ~ 6: Sun)', ylabel='Visitors', title='Visitors by Day', figsize=(8, 6))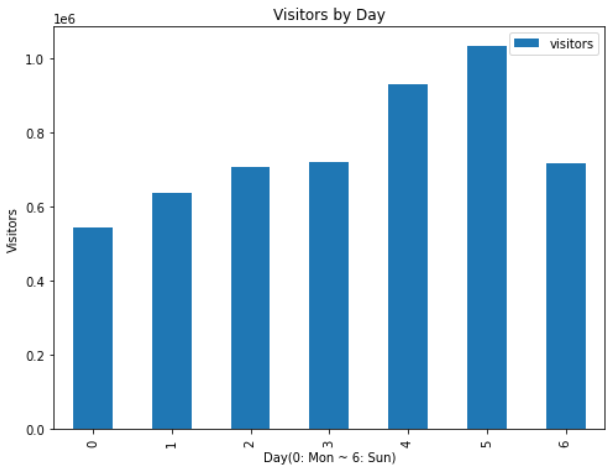
나머지 데이터셋도 모두 통합한다.
# visitor와 reserve, store information, holiday 관련 데이터 대통합
prep_df = pd.merge(data['tra'], data['ar'], how='left', on=['air_store_id', 'visit_date'])
prep_df = pd.merge(prep_df, data['as'], how='inner', on='air_store_id')
prep_df = pd.merge(prep_df, data['hol'], how='left', on='visit_date')
# test 데이터셋도 동일하게 처리
predict_data = pd.merge(data['tes'], data['ar'], how='left', on=['air_store_id', 'visit_date'])
predict_data = pd.merge(predict_data, data['as'], how='inner', on='air_store_id')
predict_data = pd.merge(predict_data, data['hol'], how='left', on='visit_date')
Feature간 상관 관계 분석을 통해 유의미한 feature가 있는지 살펴 본다.
# 주요 변수들 간의 상관 계수 확인
prep_df.corr()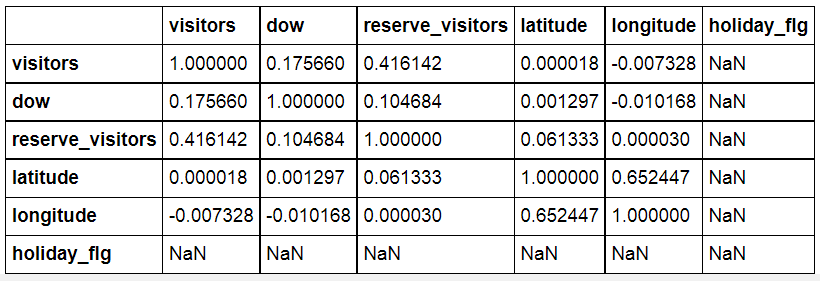
데이터 병합 과정에서 reserve_visitors와 holiday_flg 데이터에 missing value가 발생하였다.
- reserve_visitors의 경우, visitor 수를 예측하는 데 있어 예약자 수가 중요한 feature일 것으로 판단하고, 전처리 과정에서 결측치를 채우기로 한다.
- holiday_flg의 경우 전체 데이터가 약 500개 정도로, train 데이터셋 20만 개와 비교하면 매우 적어서 column을 drop시킨다.
Data Preprocessing & Feature Engineering 데이터 전처리 및 FE
앞서 날짜별 visitors 수에 관한 데이터 탐색 결과, 대략 2016년 7월 이전 데이터를 제외하기로 하였다.
# 2016년 7월부터의 데이터만 사용한다
# Using data 'visit_date' after '2016-07-01'
prep_df['visit_date'] = prep_df['visit_date'].astype(str)
prep_df = prep_df[prep_df['visit_date'] >= '2016-07-01']
# store_id와 visit_date를 기준으로 데이터프레임 정렬
prep_df['visit_date'] = pd.to_datetime(prep_df['visit_date']).dt.date
prep_df.sort_values(by=['air_store_id', 'visit_date'])
앞서 데이터 통합 및 탐색 과정에서 reserve_visitors 데이터에 missing value가 발생한 것을 확인하였다.
- 결측치 처리 과정
- 1) 적절한 값으로 결측치를 채우기 위해, 우선 현재 reserve_visitors 데이터의 분포를 확인한다.
- 2) reserve_visitors 데이터의 이상치 outlier를 탐치 및 제거한다.
- 3) 날짜별 visitor와 reserve_visitors의 비율의 평균을 구해 결측치를 보완한다.


# reserve_visitors가 200 이상인 데이터를 조회한다
trim_df = prep_df[prep_df['reserve_visitors'] >= 200]
# 위 데이터들을 prep_df에서 제거
prep_df.drop(index=[8845, 17041, 17042, 17043, 17044, 68051], axis=1, inplace=True)# 날짜별 visitors와 reserve_visitors 비율의 평균 계산
avg_vis_rate = prep_df[prep_df['reserve_visitors'].isna() == False].apply(lambda x: x['reserve_visitors'] / x['visitors'], axis=1).mean()
print("visitros와 reserve_visitors 평균 비율:", avg_vis_rate)
# avg_vis_rate을 이용해 모든 visitors 데이터에 대한 평균 reserve_visitors 데이터를 생성
avg_rev_visitors = prep_df.apply(lambda x: x['visitors'] * avg_vis_rate if pd.isna(x['reserve_visitors']) == True else x['reserve_visitors'], axis=1)
# avg_rev_visitors를 prep_df의 column으로 추가
prep_df['avg_rev_visitors'] = avg_rev_visitors
# 기존 reserve_visitors column drop
prep_df.drop('reserve_visitors', axis=1, inplace=True)
# test dataset에도 동일하게 처리
# avg_vis_rate을 이용해 모든 visitors 데이터에 대한 평균 reserve_visitors 데이터를 생성
avg_rev_visitors = predict_data.apply(lambda x: x['visitors'] * avg_vis_rate if pd.isna(x['reserve_visitors']) == True else x['reserve_visitors'], axis=1)
# avg_rev_visitors를 prep_df의 column으로 추가
predict_data['avg_rev_visitors'] = avg_rev_visitors
# 기존 reserve_visitors column drop
predict_data.drop('reserve_visitors', axis=1, inplace=True)
holiday_flg column은 drop한다.
prep_df.drop('holiday_flg', axis=1, inplace=True)
predict_data.drop('holiday_flg', axis=1, inplace=True)
visitors 통계값을 이용한 feature를 추가한다.
# store_id와 요일별 visitors 최소값을 column에 추가
tmp = data['tra'].groupby(['air_store_id', 'dow'], as_index=False)['visitors'].min().rename(columns={'visitors': 'min_visitors'})
prep_df = pd.merge(prep_df, tmp, how='left', on=['air_store_id', 'dow'])
predict_data = pd.merge(predict_data, tmp, how='left', on=['air_store_id', 'dow'])
# store_id와 요일별 visitors 평균값을 column에 추가
tmp = data['tra'].groupby(['air_store_id', 'dow'], as_index=False)['visitors'].mean().rename(columns={'visitors': 'mean_visitors'})
prep_df = pd.merge(prep_df, tmp, how='left', on=['air_store_id', 'dow'])
predict_data = pd.merge(predict_data, tmp, how='left', on=['air_store_id', 'dow'])
# store_id와 요일별 visitors 중간값을 column에 추가
tmp = data['tra'].groupby(['air_store_id', 'dow'], as_index=False)['visitors'].median().rename(columns={'visitors': 'median_visitors'})
prep_df = pd.merge(prep_df, tmp, how='left', on=['air_store_id', 'dow'])
predict_data = pd.merge(predict_data, tmp, how='left', on=['air_store_id', 'dow'])
# store_id와 요일별 visitors 최대값을 column에 추가
tmp = data['tra'].groupby(['air_store_id', 'dow'], as_index=False)['visitors'].max().rename(columns={'visitors': 'max_visitors'})
prep_df = pd.merge(prep_df, tmp, how='left', on=['air_store_id', 'dow'])
predict_data = pd.merge(predict_data, tmp, how='left', on=['air_store_id', 'dow'])
# store_id와 요일별 reserve_visitors 평균값을 column에 추가
tmp = prep_df.groupby(['air_store_id', 'dow'], as_index=False)['avg_rev_visitors'].mean().rename(columns={'visitors': 'mean_rev_visitors'})
prep_df = pd.merge(prep_df, tmp, how='left', on=['air_store_id', 'dow'])
predict_data = pd.merge(predict_data, tmp, how='left', on=['air_store_id', 'dow'])
prep_df.drop('avg_rev_visitors_x', axis=1, inplace=True)
predict_data.drop('avg_rev_visitors_x', axis=1, inplace=True)
# 불필요한 column drop
prep_df.drop('dow', axis=1, inplace=True)
predict_data.drop('dow', axis=1, inplace=True)
지금까지 처리한 feature들 간의 상관 관계를 heatmap으로 표현해 보았다.
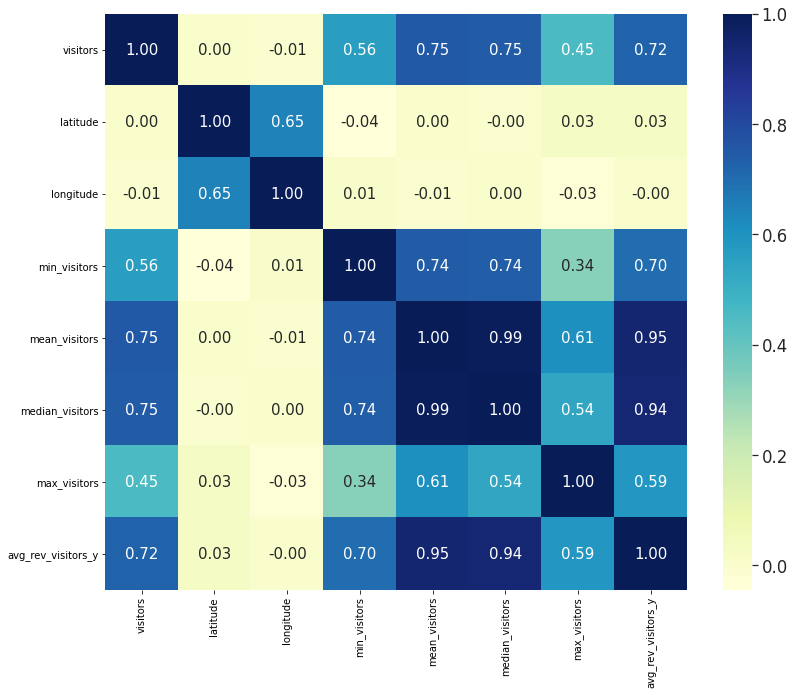
이제 나머지 범주형 데이터(categorical)를 라벨 인코딩으로 처리하고, 결측치가 있는지 확인하여 전처리 과정을 마친다.
Model Design & Train
모델은 LightGBM 4개가 예측한 값을 평균을 내는 앙상블 모델을 이용한다.
# 코드의 일부
lgb_params1 = {}
lgb_params1['application'] = 'regression'
lgb_params1['boosting'] = 'gbdt'
lgb_params1['learning_rate'] = 0.015
lgb_params1['num_leaves'] = 32
lgb_params1['min_sum_hessian_in_leaf'] = 2e-2
lgb_params1['min_gain_to_split'] = 0
lgb_params1['bagging_fraction'] = 0.9
lgb_params1['feature_fraction'] = 0.9
lgb_params1['num_threads'] = 8
lgb_params1['metric'] = 'rmse'
def do_train(train_x, valid_x, train_y, valid_y, lgb_params, rounds):
d_train = lgb.Dataset(train_x, train_y)
d_valid = lgb.Dataset(valid_x, valid_y)
watchlist = [d_train, d_valid]
lgb_model = lgb.train(lgb_params, train_set=d_train, num_boost_round=rounds,
valid_sets=watchlist, verbose_eval=1000, early_stopping_rounds = 5)
test_pred = lgb_model.predict(valid_x)
rmsle = RMSLE(valid_y, test_pred)
print(train_x.columns)
print(lgb_model.feature_importance())
return rmsle, lgb_model
train_x, valid_x, train_y, valid_y = train_test_split(X_train, y_train, test_size=0.2, random_state=74, shuffle=True)
rmsle, lgb_model1 = do_train(train_x, valid_x, train_y, valid_y, lgb_params1, 12000)
test_pred1 = np.expm1(lgb_model1.predict(X_test))
print('Test RMSLE: %.3f\n' % rmsle)
# 세 모델에서 나온 예측 값의 평균을 최종 예상치로 사용
test_pred = (test_pred1 + test_pred2 + test_pred3 + test_pred4) / 4
result = pd.DataFrame({"id": test_id, "visitors": test_pred})
최종 score는 Public 0.55432, Private 0.51447을 얻었다.
전체 코드는 여기에서 확인할 수 있다.
'공부하며 성장하기 > 인공지능 AI' 카테고리의 다른 글
| 국소 회귀(Locally Weighted Regression)란? (0) | 2021.08.29 |
|---|---|
| 선형 회귀(Linear Regression)와 경사하강법(Gradient Descent) (0) | 2021.08.23 |
| 하이퍼파라미터(Hyperparmeter)와 최적화(Optimization) (0) | 2021.08.18 |
| 과적합(Overfitting)과 규제(Regularization) (2) | 2021.08.17 |
| 앙상블 학습(Ensemble Learning)이란? (2) | 2021.08.15 |