![[한 줄 정리] 분류 모델 평가 지표](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbiwArF%2FbtrrqY3u6RR%2F4nlp6JAj6XLduGEVH5rKjK%2Fimg.png)

혼동 행렬 Confusion Matrix
- 실제 및 모델이 예측한 데이터의 분류를 나타냅니다.
- 예를 들어 이메일의 스팸 여부를 분류하는 문제가 있을 때, TP(True Positive)는 실제 스팸인 이메일을 분류기가 스팸이라고 제대로 분류한 경우입니다.
- 반대로 FP(False Positive)는 실제 스팸이 아닌 이메일을 분류기가 스팸이라고 잘못 분류한 경우입니다.

정밀도 Precision
- 분류기가 양성 샘플이라고 분류한 것 중에서 실제 양성 샘플의 비율, 즉 분류기가 스팸으로 분류한 것 중 실제 스팸인 비율입니다.
$$Precision = \frac{45}{45+5} = 0.9$$
재현율 Recall / 민감도 Sensitivity
- True positive rate, 실제 양성인 샘플 중 분류기가 정확히 분류해 낸 양성 샘플의 비율, 즉 실제 스팸인 이메일 중 분류기가 스팸으로 잘 분류한 비율입니다.
$$Recall = \frac{45}{45+20} = 0.69$$
정확도 Accuracy
- 전체 샘플 중 맞게 분류한 샘플의 비율, 즉 실제 스팸은 스팸으로, 아닌 것은 아니라고 잘 분류한 비율입니다.
$$Accuracy = \frac{45+30}{45+20+5+30} = 0.75$$
F1 score
- precision과 recall의 조화 평균입니다. 불균형한 데이터에서 accuracy보다 더 정확한 성능 지표입니다.
$$F1 score = 2\times \frac{Precision \times Recall}{Precision+Recall}$$
Fall-out
- False positive rate, 즉 실제 음성인 샘플 중 양성으로 잘못 분류한 비율, 스팸이 아닌 이메일을 스팸이라고 분류한 비율입니다.
$$Fallout = \frac{FP}{FP+TN} = \frac{5}{5+30} = 0.14$$
ROC(Receiver Operator Characteristic) curve
- Fall-out과 recall의 관계를 그린 곡선입니다. 커브가 왼쪽 위 모서리에 가까울수록 분류기 성능이 좋다고 판단합니다.
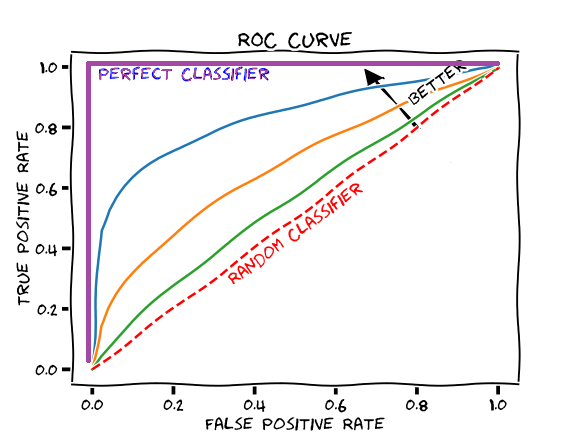
AUC(Area Under Curve)
- ROC curve 아래 면적을 나타냅니다.
- 최대값은 1이며, fall-out에 비해 recall이 클수록 1에 가깝습니다.
아래 자료를 참고했습니다.
- 데이터 사이언스 스쿨
- 책 『데이터 과학자와 데이터 엔지니어를 위한 인터뷰 문답집』
- 분류 성능 평가 지표
'공부하며 성장하기 > 인공지능 AI' 카테고리의 다른 글
| 모델 검증 방법 (0) | 2022.02.07 |
|---|---|
| ROC 곡선 vs. P-R 곡선 (0) | 2022.01.30 |
| [한 줄 정리] SMOTE (0) | 2022.01.17 |
| 피처 정규화(Feature Normalization)가 반드시 필요한 경우 (0) | 2022.01.14 |
| 머신러닝 기반 이상 탐지(Anomaly Detection) 기법의 종류 (0) | 2021.11.09 |